Requirement Definition
- Clarify business objectives and the purpose of AI utilization
- Define clear project success criteria
- Develop a project plan that balances cost, quality, and delivery timeline



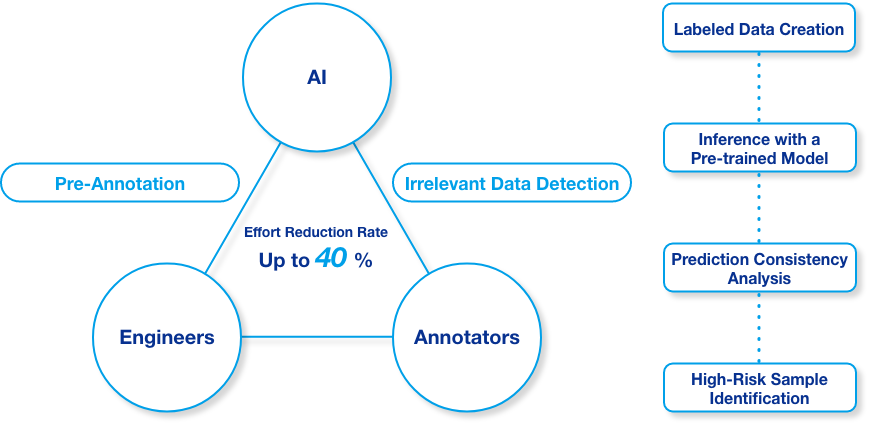
Nextremer employs a "Human-in-the-Loop" approach, fostering close collaboration between AI, engineers, and annotators. Rather than fully automating the process, we create a continuous feedback loop between humans and AI. This approach can reduce data preparation effort by up to 40%, enabling the rapid construction of large-scale datasets that meet stringent quality requirements.
Video | How We Digital Transformation and Quality Control — Project HANA
Pre-annotation is performed using pre-trained models fine-tuned by our engineers. By automating the initial labeling process, we prevent costs from scaling linearly with data volume.
AI detects inconsistencies and noise in labeled data and quantifies potential risks. Annotators focus on high-risk areas, improving overall accuracy while reducing performance variability.
Through structured collaboration between AI, engineers, and annotators, we accelerate the cycle of data preparation and model refinement. This shortens the time from project kickoff to achieving target accuracy.
*Man-hour reduction rates vary depending on project scale and environment.
To strengthen the reliability of our data annotation operations, we have conducted joint research with the University of Tsukuba. Drawing on insights gained from methodological standardization, guideline development, and reproducibility validation, we have established a quality management system that integrates academic rigor with real-world operational expertise.

We go beyond conventional data annotation services by engaging from the specification design stage through environment and tool setup. Through structured and systematic process management across every phase, we deliver solutions optimized to address each client’s unique business challenges.

We respond flexibly to unforeseen cases that arise during annotation projects. Rather than rigidly following the initial approach, we continuously refine specifications and guidelines to ensure that even complex or edge-case data can be effectively leveraged.
All client data and deliverables are used exclusively for the relevant project. We do not repurpose client data for our own products or services.
We safeguard data through strict access controls, comprehensive logging, and continuous monitoring, preventing unauthorized access and data leakage.
Upon project completion, we promptly dispose of trained models, intermediate artifacts, and any data no longer required in accordance with established data handling policies.

To improve image recognition accuracy, we executed large-scale segmentation under a tight timeline. Through technical process optimization and a robust operational framework, we efficiently processed vast volumes of complex image data, achieving high standards of quality, scalability, and speed.

To enhance crop detection accuracy, we provided comprehensive support from specification design through data annotation. Working closely with the client, we clearly defined growth stages based on the conditions of various plant organs (petals, fruits, sepals, etc.). By incorporating domain expertise into the specification design process, we achieved significant improvements in detection accuracy.

We supported AI development, including data annotation tool evaluation, selection, customization, and environment setup. To meet the requirement for multi-perspective data annotation based on complex specifications, our engineers implemented a proprietary tool with tailored configurations. This resulted in significant efficiency gains and the delivery of highly information-rich datasets.


